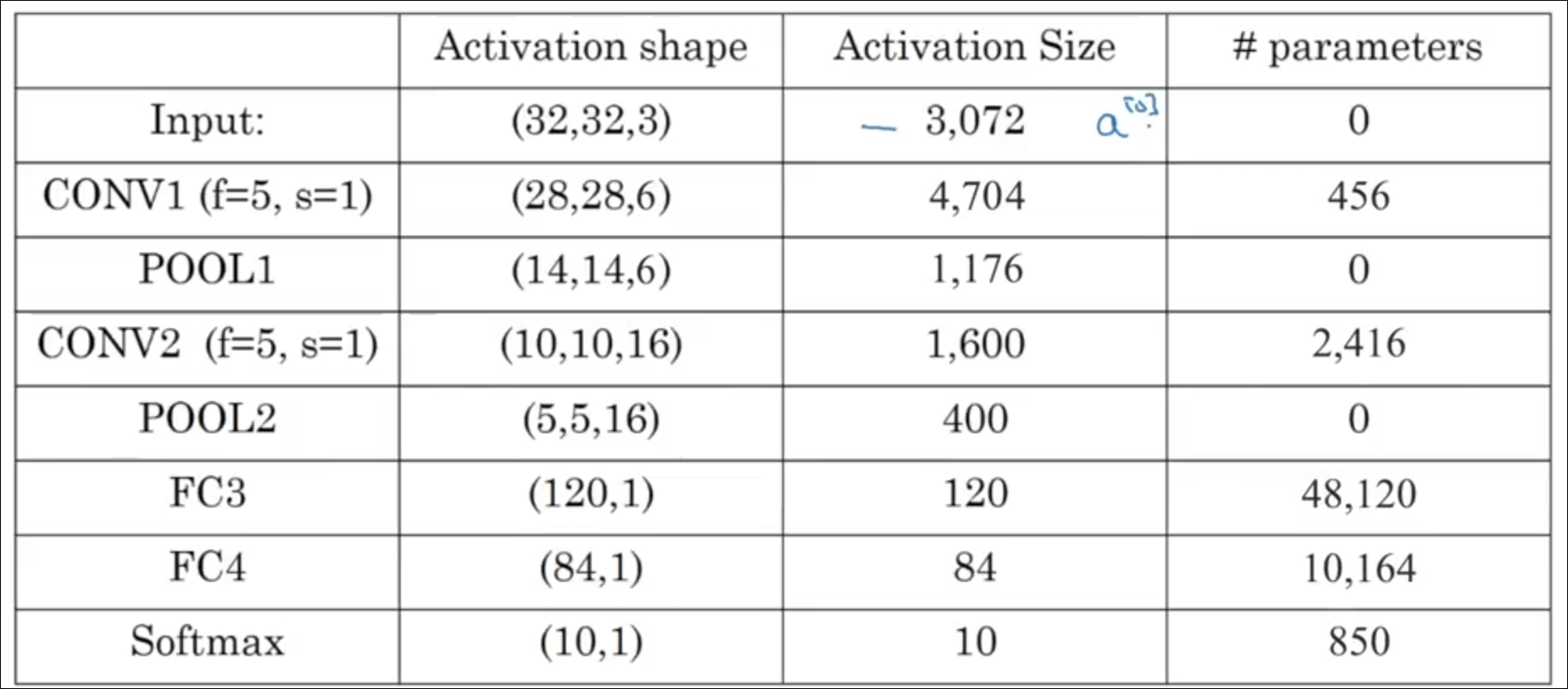
Let us understand this with the help of an example.
We start we an image of dimension 32 x 32 x 3. In layer one we use f = 5 and s = 1 to get an image of dimension 28 x 28 x 6 on which we apply max pooling using hyper-parameters f = 2 and s = 2 to get an image of dimension 14 x 14 x 6.
This first convolution layer and first pooling layer together make Layer 1. Although in some literature they are said to be different and hence they say there a two layers in total, but we are going to stick to the above definition.
For Layer 2 for the convolution part we use f = 5 and s = 1 to get a image of dimensions 10 x 10 x 16 on which we apply max pooling using f = 2 and s = 2 to get an image of dimension 5 x 5 x 16.
After Layer 2 we flatten the image in a vector of size 400. This vector then goes through a fully connected layer having weights with dimension 120, 400 to get transformed in a vector of size 120. This layer is known as Fully Connected Layer 3.
In FC4 we go from 120 to 84 which is then feed to a softmax unit for multi-classification.
As we go deeper in the network the height and width decreases and the number of channels increases.
Now we know the basics of Convolutional neural networks.
To read on why we use convolution go to - Why Convolutions ?